
(最終更新月: 2024年1月)
✔以下の疑問をお持ちの方へ向けた記事です
「Salesforceで重複ルールを設定する目的は何か?」
「重複ルールの設定方法とは?」
「重複ルールを効果的に活用するためのヒントは?」
✔当記事を読むことで得られる知識
- Salesforceにおける重複ルールの基本概念
- 重複ルールの設定とカスタマイズ方法
- 重複ルールを用いたデータ品質の維持と改善のベストプラクティス
重複ルールは、レコードの作成や更新時に重複を識別し、ユーザーに警告するか操作をブロックする機能。
データ重複による問題を最小限に抑え、効率的な顧客データベースの管理を実現するための重要な情報が満載です。
ぜひ最後までご覧ください。
定義や属性などは公式ガイドを必ず参考にしましょう。
当記事では、主にその使い方を具体例とともに解説します。
筆者プロフィール
![]()
【現職】プロダクトマネージャー
プロダクトマネージャーとして、Apex・Visualforceの開発エンジニアとして、以下のようなプロジェクトに従事してきました
- 新規事業の立ち上げに伴うビジネスプロセス構築とSalesforceのカスタマイズ
- SFDXを活用した大規模リリース
- Visualforce等による一般ユーザー向けサイト・アプリケーションの構築
相談・業務の依頼も承ります。ご質問・ご希望をお問い合わせください。
重複ルールの基本
こちらでは、「重複ルール」についてお伝えしていきます。
「重複ルール」を理解することで、データベースの整合性の維持やデータ品質の向上に役立つでしょう。
- 重複ルールとは何か
- 重複ルールの役割と重要性
- 重複検出と重複防止の違い
重複ルールとは何か
重複ルールとは、同一または非常に類似したレコードが生成されるのを検出し、必要に応じて防止するルールのこと。
このルールは、複数のフィールドの組み合わせをチェックすることで、新しいレコードが既存のものと重複していないかを評価します。
たとえば、顧客のレコードを作成する際、EmailとPhone Numberの組み合わせをチェックし、もし重複があった場合に警告を発するように設定できるのです。
重複ルールの役割と重要性
重複ルールは、データベース内で正確な情報を保つために重要な役割を果たします。
ルールの設定によって、以下のようなことが可能だからです。
- 無意識のうちに同じ顧客に対して二重にレコードを作成するミスを防げる
- マーケティング活動で同一人物に複数回アプローチしてしまうといった非効率を排除できる
このように、データの品質を高めることは、顧客満足度向上や業務プロセスの最適化に直結します。
重複検出と重複防止の違い
重複検出とは、既に存在するデータに対して新しく入力されたデータが重複していないかを確認するプロセスです。
一方、重複防止は、重複検出と同時に、重複するレコードがシステムに保存されること自体を事前に阻止する役割を持ちます。
重複防止ルールにより、重複を含むデータの保存を拒否し、適切なアクションをユーザーに促すメッセージを表示できるのです。
重複ルールの設定方法
「重複ルールの設定方法」について具体的に見ていきます。
正しい重複ルールの設定によって、データ整合性を高め、運用コストを削減できるでしょう。
- 新しい重複ルールの作成手順
- マッチングルールの設定
- 重複レコードの識別と処理オプション
新しい重複ルールの作成手順
重複ルールを新しく作成するには、システムやソフトウェアによって手順が異なりますが、以下のステップに従って進めることが一般的です。
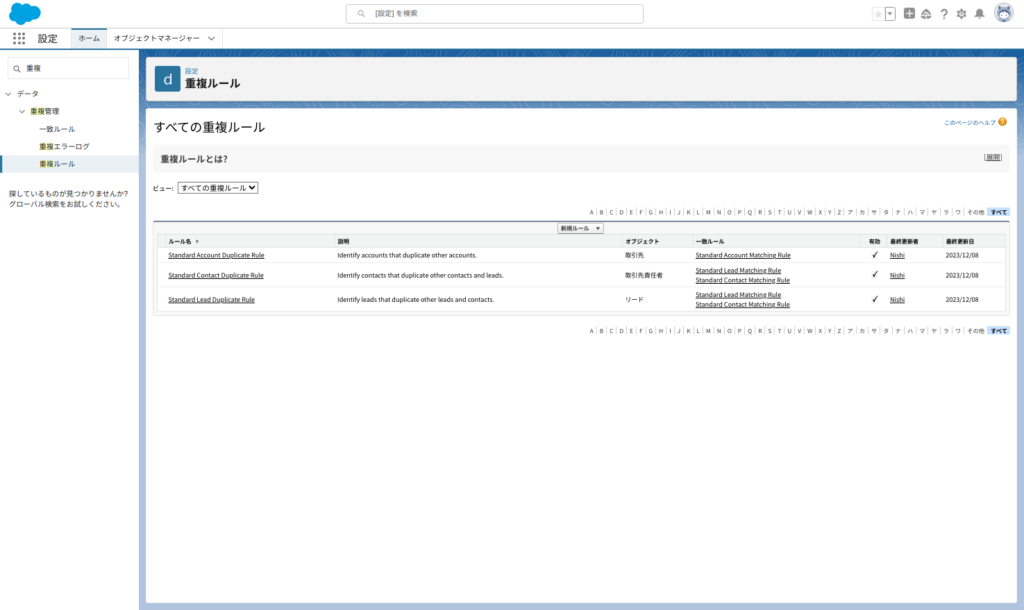
設定 > 重複ルール > 新規ルール
ルールの設定は以下4つのオブジェクトで可能です。
- リード
- 個人
- 取引先
- 取引先責任者
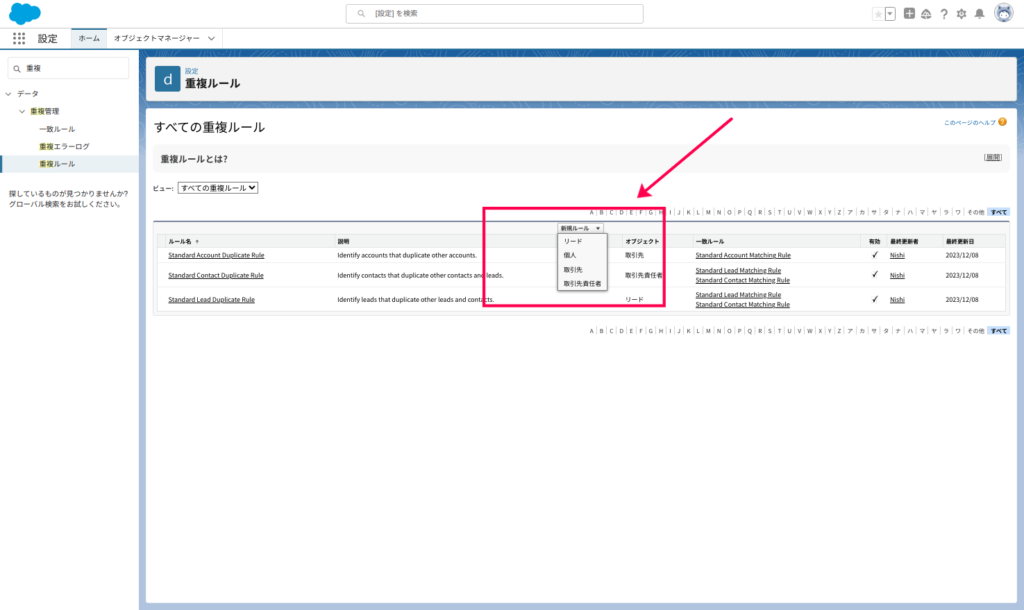
オブジェクトを選んだら、必要な情報(チェックするフィールド、チェックの条件など)を入力し、ルールを定義しましょう。
この際には、次章で説明している一致ルールも必要です。
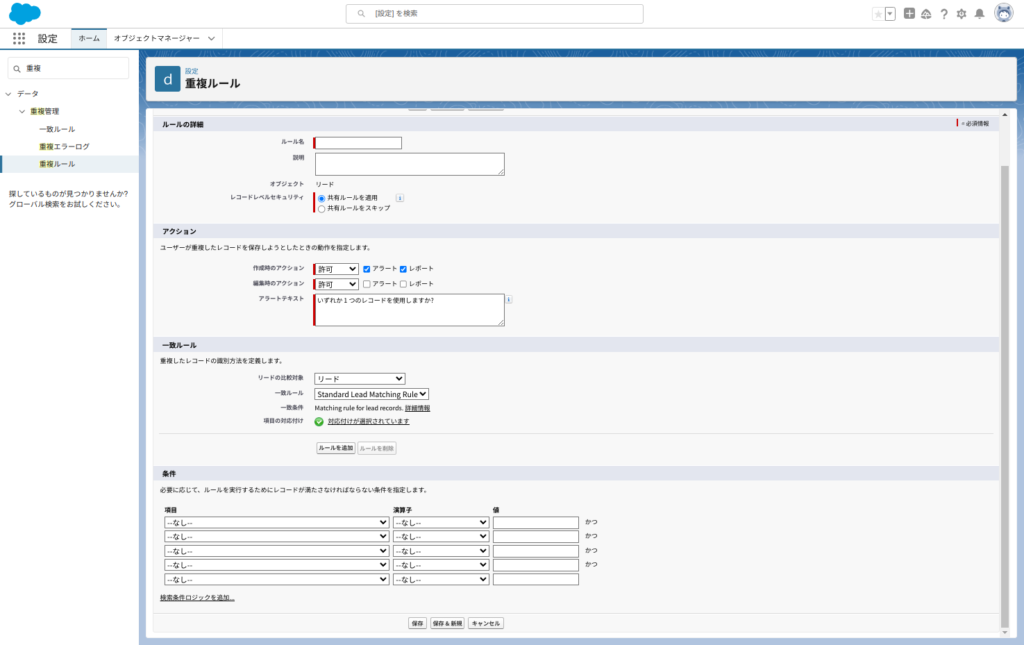
完成したら、ルールを保存し、必要に応じて有効化します。
一致ルールの設定
一致ルールは、重複を判定するための条件を設定する場所です。
たとえば、顧客の姓(Last Name)と電話番号(Phone Number)を組み合わせたマッチング条件を設定できます。
条件は、フィールド間の論理演算を用いて複雑にすることも可能。
この設定は、システムの重複チェック機能に大きく依存し、データ一致の正確さを左右するため、慎重な設計が求められます。
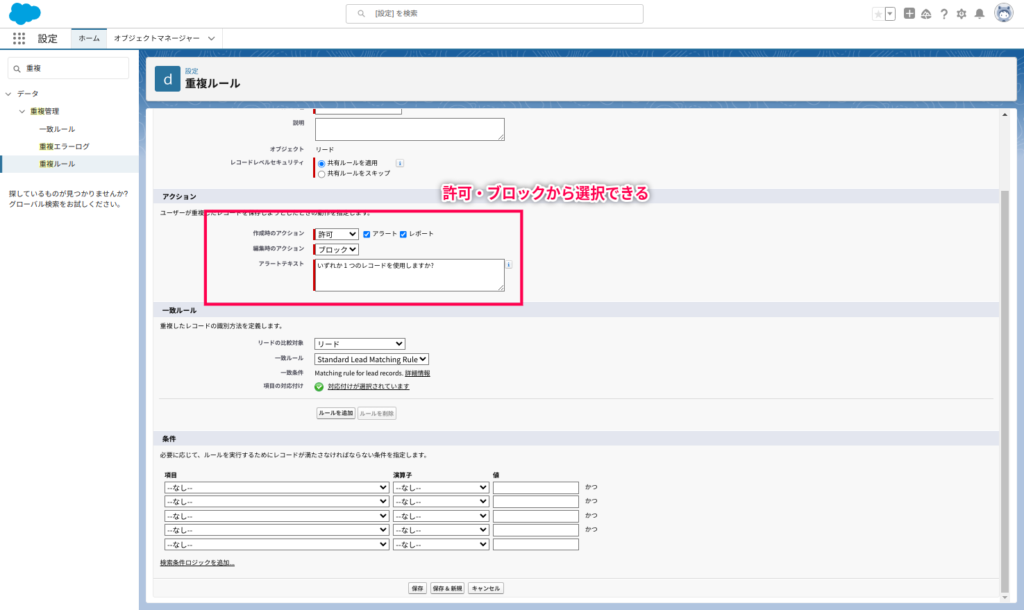
重複レコードの識別と処理オプション
重複レコードが識別された場合、どのように処理するかを決める必要があります。
処理オプションとしては、以下の2つ。
- 許可(アラートorレポート)
- ブロック
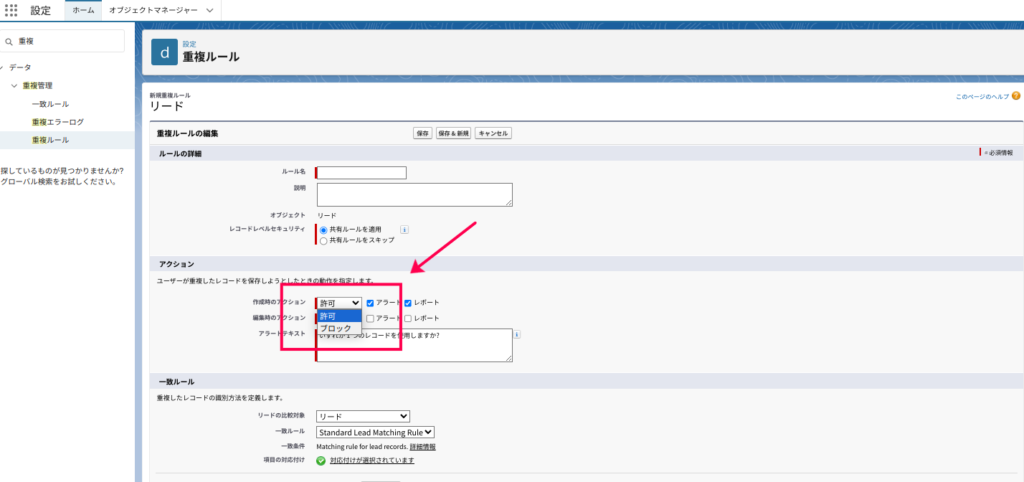
処理オプションは、システム側でレコードを保存する前に一連のルールを適用します。
重複レコードの取り扱い方はビジネスプロセスごとに異なるため、組織のポリシーやワークフローに合わせたカスタマイズが不可欠です。
重複ルールの実践的活用
ここでは、具体的な場面での「重複ルールの実践的活用方法」について説明します。
実践的な活用により、データ管理の効率性が向上し、不必要なエラーを削減することが可能です。
- レコード作成とインポート時の重複チェック
- ビジネスプロセスとの統合
- ユーザーへの通知とガイダンス
レコード作成とインポート時の重複チェック
データをシステムに新しく作成する際や、外部からのデータインポートをおこなう際には、重複チェックが非常に重要です。
重複ルールを有効にしておくことで、これらのプロセスにおけるエラーの可能性を低減できます。
例えば、顧客情報をインポートする際には、CSVファイルなどのデータセット内で Email フィールドの重複チェックをおこなってからインポートを実行することが一般的です。
これを自動化するには、インポートツールまたはAPIの設定において、重複ルールに従ってデータを検証し処理するよう設定することが可能です。
ビジネスプロセスとの統合
重複ルールは、ビジネスプロセスに密接に統合できます。
顧客サービスチームがCRMに問い合わせ履歴を入力する際、既存の顧客情報と重複しないようできるからです。
そのためのひとつの方法として、ワークフロー自動化ツールによって、問い合わせが登録されるたびに、顧客データベースとのマッチングをし、重複していないことを確認するプロセスを設定しましょう。
これにより、不整合を事前に防ぎ、時間と労力の節約につながります。
ユーザーへの通知とガイダンス
重複が発生したときにユーザーを適切に案内することは、エラーの是正とデータ品質の維持に役立ちます。
システムが重複を検出した場合、ユーザーに対して明確な指示を表示し、どのアクションを取るべきかを伝えられるからです。
このガイダンスは、ポップアップメッセージや特定の作業領域内に表示されるアラートとして提供されることが多く、ユーザーが誤ったデータ入力を未然に防ぐ手助けとなります。
重複ルールのベストプラクティス
効果的な「重複ルールのベストプラクティス」についてのアドバイスを共有します。
これらを参考にすることで、組織内のデータ管理手法をより洗練させられるでしょう。
- 効果的な重複ルール設計のヒント
- データ品質の維持と改善
- レポートと監視を通じたデータ管理
効果的な重複ルール設計のヒント
重複ルールを設計する際には、以下のヒントが有用です。
- どのフィールドがビジネスにとって重要かを把握
- そのフィールドを優先して重複の検出に用いる
- レコードが異なるソースから来る可能性があることを考慮し、フレキシブルなマッチング条件を採用
データ処理のスピードを考慮し、無駄な検証は避け、効率的なルールセットに絞り込むべきです。
データ品質の維持と改善
データ品質を維持し改善するためには、重複ルールを定期的に見直し、更新することが重要です。
データの傾向やビジネスの変化に応じて、ルールの調整が必要になります。
データクレンジングや正規化を定期的におこない、データ入力時のガイドラインをユーザーに提供することで、不正確なデータの入力を減らすことが可能です。
レポートと監視を通じたデータ管理
データの重複を管理するうえで重要なのは、レポートの作成とデータ監視の実施です。
上手く活用することで、重複ルールの精度を向上させるための施策を講じられます。
- 定期的なレポート: どの種類の重複が最も頻繁に発生しているか、またその原因を分析
- 監視ツール: リアルタイムでデータをチェック
異常があればすぐにアクションを起こせる体制を整えることも有効です。
重複ルールのトラブルシューティング
最後に、「重複ルールのトラブルシューティング」方法について考えてみましょう。
適切なトラブルシューティングによって、システムおよびデータの安定性を保てます。
- 一般的な問題とその解決策
- パフォーマンスと効率性の最適化
- 重複ルールのメンテナンスと更新
一般的な問題とその解決策
データの重複チェックにおいては、さまざまな問題が発生することがあります。
たとえば、同姓同名の異なる顧客を重複と誤認定してしまうケースです。
この問題に対処するには、マッチング条件に更なる識別情報を追加することが考えられます。
こうした問題解決には、ルールの細分化や追加のフィールドを設定することで対応しましょう。
パフォーマンスと効率性の最適化
重複チェックのパフォーマンスを最適化するには、データセットのサイズやクエリの効率への考慮が重要です。
とくに大規模なデータベースでは、適切なインデックスの設定やバッチ処理の利用がパフォーマンス向上に役立ちます。
また、不必要なフィールドをマッチング条件から除外することで、チェックのスピードを向上させることが可能です。
重複ルールのメンテナンスと更新
重複ルールは、ビジネス環境やデータ環境の変化に応じて定期的にメンテナンスおよび更新する必要があります。
ルールの定期的な見直しにより、変化する条件に適応し、データの品質を保てます。
また、新たなデータフィールドが追加された場合や、既存のデータパターンが変化した場合にも迅速に対応することが重要です。
これにより、継続的なデータ整合性の確保と、エラーの発生を最小限に抑えられます。
まとめ
データ管理において重複ルールは不可欠であり、データベースの整合性を保ち、ビジネス運営の効率化に寄与します。
重複データの管理は煩雑であるかもしれませんが、しっかりとしたルール設定と定期的な見直しをおこない、多くの問題を未然に防げるでしょう。